Did you know that Iran had tax revenues greater than its GDP for three years in the late 1980s? Or at least that’s the impression you’d get if you — like many researchers — were to combine tax data from the IMF’s Government Financial Statistics and the GDP series from the IMF’s International Financial Statistics. That’s an extreme case, but it turns out that a whole lot of tax data used by researchers is, well, not very good. (In this particular case, the culprits are twofold: an inaccurate GDP series for Iran from the IFS and the fact that the GFS does not distinguish resource and non-resource taxes. However, the problems with the tax data employed by researchers are pervasive and stem from multiple sources.)
Back in 2004, I set up a project at a small Oxford think tank to examine the role of taxation in development. Two problems were quickly apparent: the relative neglect of this important policy area, and the terribly weak data. Fast forward ten years and the International Centre for Tax and Development (ICTD) has launched its Government Revenue Dataset, which we hope will prove to be both a substantial step in addressing the second of these problems and a tool to ameliorate the first. But this is only a temporary fix: international commitment is required to ensure much better tax data is available in future.
You can find all the details of creation of the new dataset and an outline of its features, in our ICTD working paper. Andrew Goodall (Charles U., Prague) did much of the important early work, while Wilson Prichard (U. Toronto and Research Director, ICTD), with great help from Fariya Mohiuddin, Vanessa van den Boogaard, and Ava-Dayna Sefa, has driven the project to completion over the last two years, leading the often painstaking work of decisions around inclusion, categorization, and labelling that have turned out to be necessary to make this a valuable tool for researchers.
Extending Coverage
In summary, the dataset reflects three stages of work:
- Collation of the range of existing global and regional datasets
- Addition of data extracted from IMF country reports and Article IV documents (that is, data retrieved from the documents published following the IMF’s annual consultations with national governments)
- Working with the data to produce a consistent, relatively high-quality ‘first choice’ series
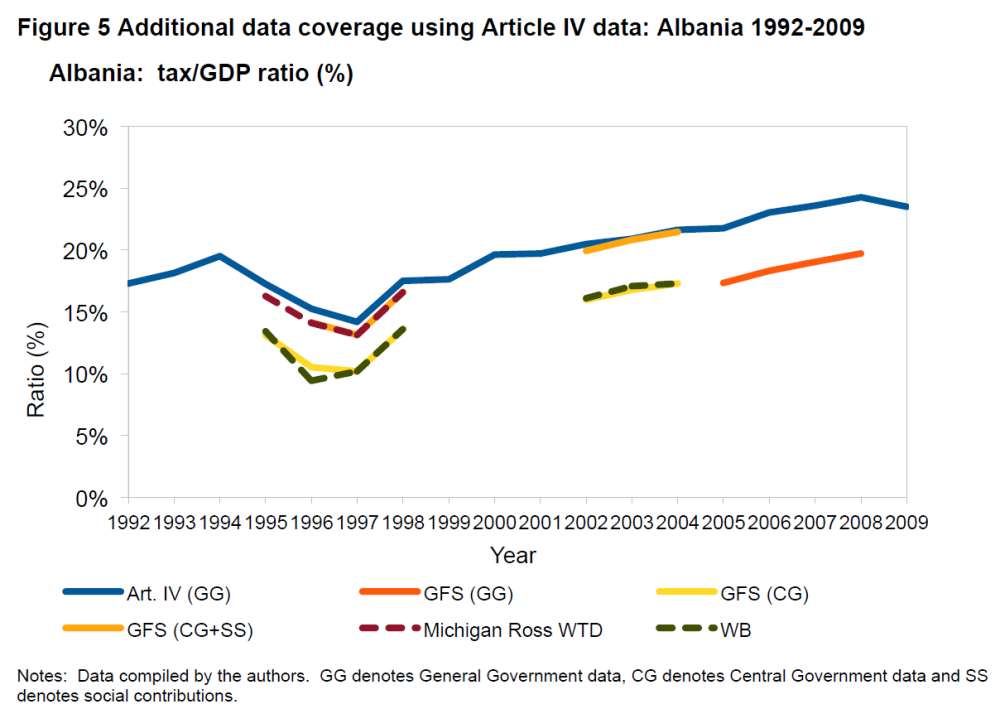
Stage 2 is particularly important in extending coverage, especially for low-income countries, and to be able to disaggregate resource and non-resource revenues. Our figure 5 from the paper provides a clear example in the case of Albania: while Article IV data is complete for nearly two decades, any other series covers only a few years.
Addressing GDP Problems
A particular issue in producing a consistent dataset was the standardization of underlying GDP series. Much has been written about GDP data quality and about rebasing in particular, and so it is no surprise that this is a problem for tax data where a GDP denominator is typically used (not least, to allow comparisons between countries and over time). Our figure 6 shows just how important standardization is in the case of Ghana. The difference in implied tax-to-GDP ratio is, at the extreme, close to 10 percent of GDP: this really matters.
The use of inconsistent GDP series in the World Bank’s World Development Indicators and in IMF country reports creates a story of sharp falls in tax/GDP which is not present either in IMF Government Financial Statistics or in the African dataset created by IMF researchers Keen and Mansour. The adjusted series are much more consistent (as you would hope, given the same ultimate source at national level). On the one hand, they now show broadly rising tax/GDP; on the other hand, the ratio never reaches the 15 percent level that the IMF and others have often used as a rule of thumb for state fragility.

Bad Data, Bad Research?
It is a real concern that researchers in and outside major international organizations have for a long time now either relied on data that is recognized to be problematic, or have constructed ad hoc alternatives that have not been fully open to public scrutiny — and which have been shown to include meaningful errors. What we think we know and understand about tax is open to serious questions.
In fact, some of the first papers to use the new data suggest data issues have led to inaccurate research findings — with significant policy implications. Prichard, Salardi, and Segal confirm the existence of a political resource curse; while McNabb and LeMay-Boucher shed new light on the growth impact of tax structure.
More controversially, Morrissey, Prichard, and Torrance are unable, with the new dataset, to replicate the findings of previous literature on aid and tax and conclude instead that there is “no evidence to justify claims that grants reduce tax effort.” And Paul Clist searches with a range of techniques for the same evidence, but finds instead “a modest but positive effect from foreign aid on domestic tax revenue.”
At the dataset launch event in Washington, the authors of the studies being questioned reacted angrily to these findings. The advantage of the new, fully public ICTD dataset is that it is now straightforward to adjudicate on these questions. Researchers have now exchanged Stata do-files, allowing them to replicate and check each other’s work. Watch this space for results of that exchange.
A Better Tax Data Future?
The data in the ICTD’s Government Revenue Dataset are not perfect. Individual data points cannot be more accurate than the original data collected by national institutions. They can, however, be organized and used in such a way as to eliminate introduced errors — for example from combining series badly, or from GDP series breaks — so that overall they reflect the original picture more closely. And this can be done in a transparent way such that researchers can trace the basis of decisions and produce fully replicable results.
To quote our conclusions: “The benefits of the new ICTD Government Revenue Dataset are, we think, substantial: irrespective of minor imperfections, the ICTD GRD provides both researchers and policymakers with a dataset that is dramatically more complete and more accurate than existing options. This, in turn, stands to provide a much more reliable foundation for research, while providing a much clearer picture of historical patterns of tax collection.”
At the launch event, senior statisticians from both the IMF and OECD highlighted that working with regional and national institutions to improve the accuracy of original data is now a major focus. The conversation over the coming months will focus on the scope for partnership to ensure that the ICTD dataset, or something similar that meets the needs of researchers, is maintained over time and continues to develop as a resource.
Those concerned about data, research, and policy will want to keep a wary eye on this: divergence between the data used for research and the underlying reality, can result in unnecessary errors in our understanding of good tax policy for development.
Disclaimer
CGD blog posts reflect the views of the authors, drawing on prior research and experience in their areas of expertise. CGD is a nonpartisan, independent organization and does not take institutional positions.



